cc— and it is adding an alternate layer: distributed inference and edge AI infrastructure.
The shift is happening because AI workloads are changing.
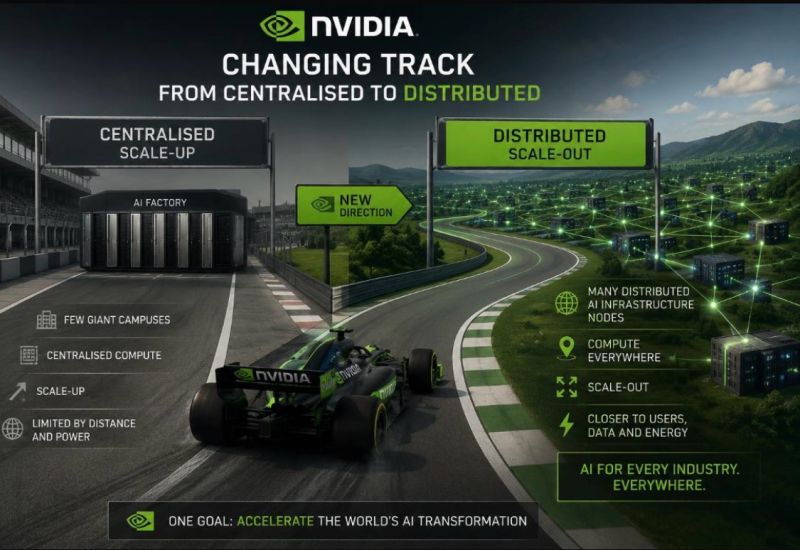
In the first phase of generative AI, the priority was training giant foundation models. That favored massive centralized GPU clusters and hyperscale data centers. NVIDIA built this world around DGX SuperPODs, NVLink fabrics, and “AI factories.”
Now the bottleneck is increasingly inference — running AI continuously, close to users, devices, robots, factories, vehicles, and enterprises. That requires compute to move outward from a few giant campuses to thousands or millions of distributed nodes.
NVIDIA’s sudden core strategy change has several parts:
1. From hyperscale-only to edge + cloud
NVIDIA is pushing AI compute into desktops, enterprises, telecom edges, factories, and even homes. DGX Spark and DGX Station are examples of “personal AI supercomputers” designed for local AI execution rather than centralized cloud-only processing.
2. From owning infrastructure to orchestrating ecosystems
Instead of competing directly with AWS/Azure as a centralized cloud provider, NVIDIA is increasingly becoming the operating layer across many distributed GPU providers. DGX Cloud Lepton is effectively a marketplace connecting developers to GPUs spread across multiple cloud and edge providers globally.
3. Edge inference near users
NVIDIA and partners are deploying smaller inference clusters closer to users for low latency AI applications — robotics, autonomous systems, industrial AI, digital twins, and AI agents. The Akamai Inference Cloud partnership is one example of distributed edge inference infrastructure.
4. AI everywhere, not just in mega campuses
The company is now talking about “AI factories” as a global fabric rather than a few hyperscale campuses. The idea is:
* centralized GPU clusters for training
* distributed infrastructure for inference and real-time AI
This hybrid architecture reduces latency, improves privacy, lowers bandwidth costs, and avoids concentrating all compute in a few regions.
5. Networking as the new moat
NVIDIA focus is to become the networking and orchestration backbone of distributed AI.
Key Aspects of NVIDIA’s Distributed Data Center Strategy:
AI Factories & Inter-Data Center Networking:
Enabling thousands to millions of GPUs to operate as a single engine using NVIDIA Spectrum-X Ethernet and Quantum InfiniBand, allowing for “multi-data center” training across geographically separated sites.
Long-Haul Training Efficiency:
Using NVIDIA NeMo Framework 25.02 and Megatron-Core 0.11, Nvidia supports efficient, multi-site AI model training, achieving 96% scaling efficiency over 1,000 kilometers apart.
800 VDC Infrastructure:
Introducing 800 VDC (volt direct current) architecture to power distributed, high-density AI racks, reducing energy losses and supporting up to 1 MW per rack.